


Machine Learning
El nombre de Machine Learning es derivado del estudio de sistemas que pueden aprender de los datos. Es la capacidad de un sistema para generalizar sobre la base de la experiencia. Consiste en el uso de estas generalizaciones para dar respuesta a las cuestiones relativas a datos recopilados con anterioridad, así como datos que no se han encontrado antes.
Combina y se aplica en multitud de aéreas de conocimiento: estadística, reconocimiento de patrones, inteligencia artificial, minería de datos, etc... Por aplicación de distintos tipos de algoritmos estos sistemas son capaces de extraer conocimiento de forma automatizada: clasificación, agrupamiento, regresión para la generación de predicciones. Tiene un gran número de posibles aplicaciones que resuelven problemas realmente complejos: sistemas de recomendación, predecir la demanda de un producto, predecir el precio de una vivienda, etc.
Grandes corporaciones emplean el Machine Learning en sus sistemas: Google, Facebook, Linkedin, Netflix, Amazon.
> Porfolio Características técnicas Forecasting Sistemas de recomendación Sentiment Analysis

CARACTERÍSTICAS TÉCNICAS
En la suite de Pentaho contamos Pentaho Data Integration (PDI) y Weka que permiten la integración con las ultimas tecnologías en esta disciplina.
Weka
Es la herramienta dentro de la suite analítica de Pentaho para el análisis predictivo, contiene un conjunto de algoritmos para el aprendizaje automático para las tareas de minería de datos. Estos algoritmos o bien se pueden aplicar directamente a un conjunto de datos o mediante llamadas de su propio código java. Weka dispone de un conjunto de herramientas para el procesamiento previo de los datos, clasificación, regresión, clustering, reglas de asociación, y la visualización.
Lenguajes Python y R
En Python podemos emplear paquetes orientados a Machine Learning como pandas, scikit-learn, Pylearn2, ...
Si utilizamos R disponemos de varias librería como e1071, rpart, igraph, nnet, randomForest, caret, kernlab,gbm, earth, mboost, ...
Big Data
Disponemos de Herramientas de machine learning con Big Data: Apache Mahout, MLib que opera sobre Apache Spark
Forecasting: Previsión de la demanda con modelos Holt-Winters y ARIMA

Contamos con especialistas en la aplicación de modelos Holt-Winters y ARIMA para la previsión de la demanda, ajustando el nivel de Stock y reduciendo el Working Capital.
El modelo autorregresivo integrado de promedio móvil o ARIMA es modelo estadístico que utiliza variaciones con el fin de encontrar patrones para una predicción hacia el futuro. Se trata de un modelo dinámico de series temporales, es decir, las estimaciones futuras vienen explicadas por los datos del pasado y no por variables independientes. El modelo ARIMA puede generalizarse aun mas para considerar el efecto de la estacionalidad, en ese caso, hablamos de un modelo SARIMA.
Holt-Winters (método de alisado exponencial) es una manera de pronosticar la demanda de un periodo dado. A diferencia de muchas otras técnicas, el modelo Holt-Winters puede adaptarse fácilmente a cambios y tendencias, así como a patrones estacionales. En comparación con otras técnicas, como ARIMA, el tiempo necesario para calcular el pronóstico es considerablemente más rápido, funciona mejor con serias más cortas.
Sistemas de Recomendación: Sugerencias personalizadas para cada tipo de usuario mediante técnicas de filtrado colaborativo

Hoy en día existen una infinidad de posibilidades en casi todos los aspectos de nuestras vidas, tenemos que tomar decisiones desde elegir un coche hasta nuestra vivienda. En estas condiciones, la posibilidad de recomendar una elección es algo valioso, más aún si esa opción está personalizada para la persona que recibe la recomendación.
Utilizando técnicas de Machine Learning somos capaces de atraer a adquirir un producto en función de su relevancia para nuestras necesidades y deseos personales. Para realizar esta labor se utilizan entre otras técnicas de filtrado colaborativo. El filtrado colaborativo centra su lógica en las características del usuario (compras anteriores, preferencias, calificaciones que ha dado de otros productos) y se busca usuarios que han tomado decisiones parecidas. Los productos que han tenido éxito con usuarios similares, seguramente también le interesarán al nuevo usuario.
Ejemplos:
- Amazon: Productos relacionados
- Netflix: Recomendación de películas
- Google: Autocompletado de búsquedas
- Linkedin: Recomendación de contactos
Sentiment Analysis: Mejorando el marketing de la empresa gracias al análisis de sentimiento
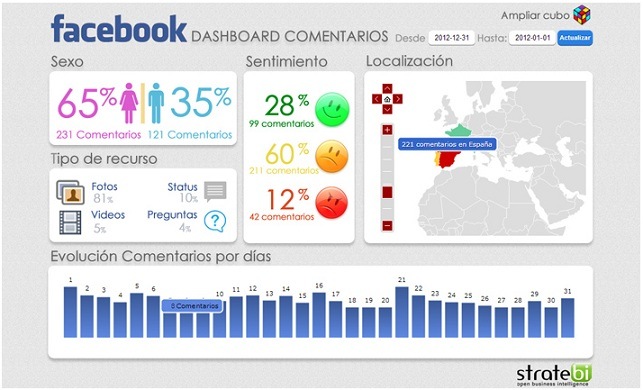
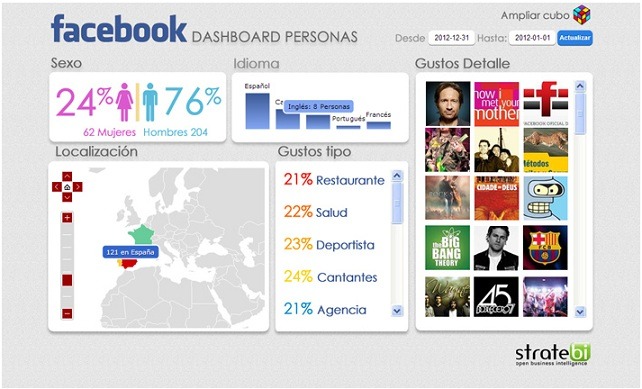
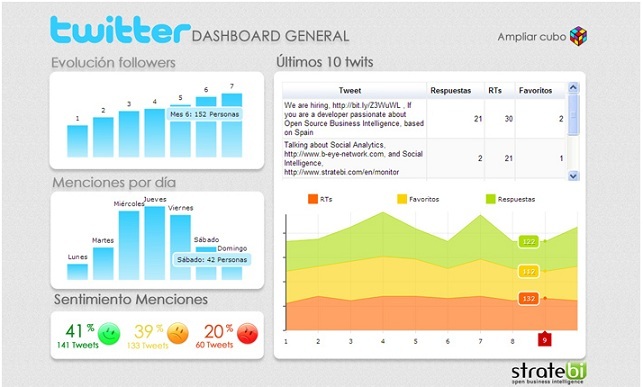
Gracias al análisis de sentimiento se puede medir la repercusión de una marca o producto dentro de las redes sociales. Esta técnica también conocida como (minería de opinión, clasificación de sentimientos o computación afectiva), consiste en extraer y clasificar la información subjetiva (opiniones, ideas) en materias. Es decir, dados unos datos de origen con un formato de texto, en los que aparecen opiniones o sentimientos sobre distintas entidades u objetos, permite extraer las opiniones de los mismos y clasificarlas. Se podría decir que se trata de un tratamiento computacional de las opiniones, sentimientos y fenómenos subjetivos de los textos.
Esta técnica utiliza el lenguaje natural, ya que es el que utiliza el usuario, y tratar computacionalmente este lenguaje conlleva ciertos problemas como la ambigüedad de las palabras, ya que dependen fuertemente del contexto. Los retos a los que se enfrenta son la extracción de las características sobre las que se está opinando y la clasificación de dichas características.
Nuestra solución permite generar beneficios en el departamento de marketing de una compañía, mejorando la eficiencia a hora de analizar el impacto de las campañas comerciales, analizando si se obtienen comentarios positivos o negativos en el conjunto de redes sociales (Twitter, Facebook, ...)