


Antes de realizar un curso o seminario, escuchamos las necesidades reales y objetivos de cada cliente, para adecuar la formación y obtener el mayor aprovechamiento posible. Ajustamos cada curso a sus necesidades.
Somos también especialistas en formaciones 'in company' adaptadas a las necesidades de cada organización, donde el aprovechamiento para varios asistentes de la misma compañía es mucho mayor. Si es tu caso, contacta con nosotros.
Ponemos a disposición también plataforma Cloud con todas las herramientas instaladas y configuradas, listas para la formación, incluyendo ejercicios, bases de datos, etc... para no perder tiempo en la preparación y configuración inicial. ¡Sólo preocuparos de aprender!
Ofrecemos también la posibilidad de realizar formaciones en base a ‘Casos de Uso’
Se complementa la formación tradicional de un temario/horas/profesor con la realización de casos prácticos en las semanas posteriores al curso en base a datos reales de la propia organización, de forma que se puedan ir poniendo en producción proyectos iniciales con nuestro soporte, apoyo al desarrollo y revisión con los alumnos y equipos, etc…
En los 10 últimos años, ¡hemos formado a más de 250 organizaciones y 3.000 alumnos!
Ah, y regalamos nuestras famosas camisetas de Data Ninjas a todos los asistentes. No te quedes si las tuyas





Curso de Pentaho Data Integration
Curso de Pentaho Data Integration
Objetivo
La extracción, transformación y carga (ETL) de los datos es la clave del éxito en un sistema BI, que permite gestionar la calidad de los datos de forma adecuada.
En este curso te contaremos algunas de las mejores prácticas que recomendamos durante el diseño de los procesos ETL como:
Centralización de los procedimientos, de forma que se asegure la coherencia y homogeneidad de los datos intercambiados desde las distintas fuentes.
Evitar la redundancia de cálculos: si existe el dato previamente calculado en las bases de datos operacionales, no debe volver a realizarse el cálculo en la extracción. Esta premisa pretende conseguir un doble objetivo.
Establecimiento de puntos de "control de calidad" y validación.
Implementar procesos de recarga de la información, ante posibles errores en la información inicial.
Contemplar la posibilidad de utilizar tablas intermedias con el nivel más atómico de la información a tratar.
Además, repasaremos los elementos más importantes y usados de la herramienta de ETLs de Pentaho: Kettle o Pentaho Data Integration.
Accede a nuestra DEMO BI Completa

Compruebe el potencial de nuestras soluciones
En Stratebi hemos creado un gran número de Demos Online, para que pueda ver algunos ejemplos realizados para varios sectores, con datos públicos. Descubra de forma práctica la cantidad de posibilidades que ofrecen nuestras soluciones y desarrollos.
En la demo, podrá evaluar las herramientas LinceBI (STPivot, STDashboard o STCard), un conjunto de herramientas desarrolladas por Stratebi y que dotan de gran potencia a nuestras soluciones.
Solicite una clave de acceso Accede a la Demo BI
Público objetivo
Observaciones
Data Quality e integración con Pentaho
Novedades Pentaho Data Integration 9.0
Las principales novedades de PDI 9.0 son las siguientes:
- Los usuarios pueden acceder y procesar datos de múltiples clústeres de Hadoop, de diferentes distribuciones y versiones, todo desde una sola transformación e instancia de Pentaho.
- Además, dentro de Spoon, los usuarios ahora pueden configurar tres configuraciones distintas de clúster, todas con referencia a un clúster específico, sin tener que reiniciar Spoon.
- La nueva interfaz de usuario brinda una experiencia mejorada para la configuración de clústeres y para la creación de conexiones seguras.
- Admite las siguientes distribuciones: Hortonworks HDP v3.0, 3.1; Cloudera CDH v6.1, 6.2; Amazon EMR v5.21, 5.24.
El siguiente ejemplo muestra un Multi-clúster implementado sobre el mismo pipeline de datos con conexión a los clústeres Hortonworks HDP y Cloudera CDH. 
Casos de uso y beneficios
· Permite el procesamiento de Big Data híbrido (local o en la nube), dentro de un mismo pipeline de procesamiento de datos.
· Simplifica la integración de Pentaho con clústeres de Hadoop, mediante una experiencia de usuario mejorada para configuraciones de clúster.
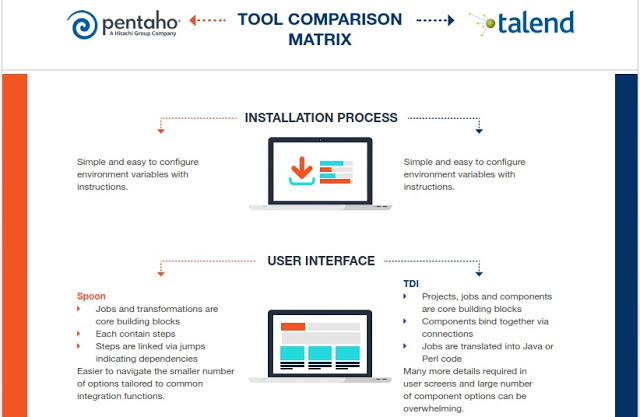
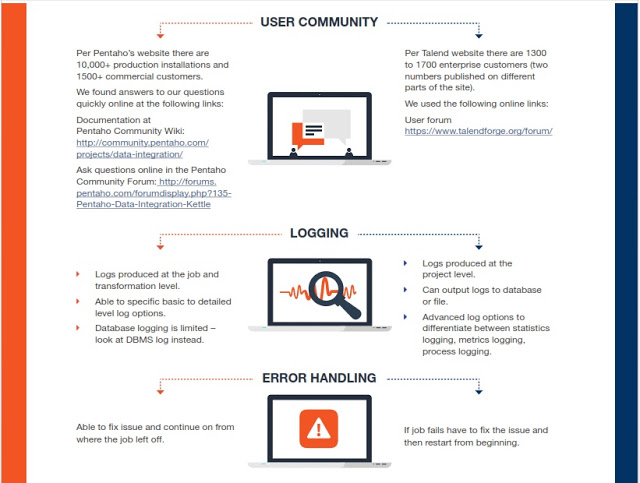
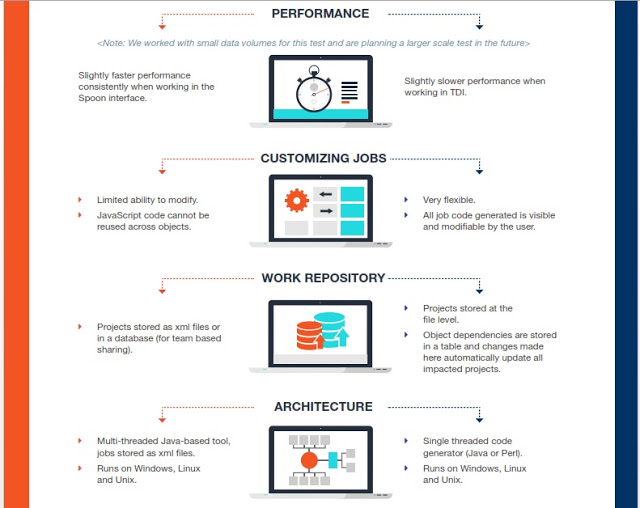
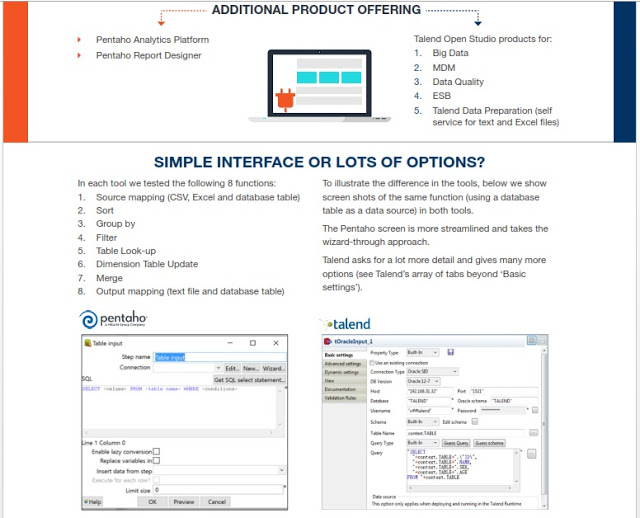
Comparativa Kettle (Pentaho Data Integration) y Talend
Tanto Kettle como Talend son grandes herramientas, muy visuales, que nos permiten integrar todo tipo de fuentes, incluyendo también Big Data para hacer todo tipo de transformaciones y proyectos de integración o para preparar potentes entornos analíticos, también con soluciones Open Source como podéis ver en esta Demo Online , donde se han usado Kettle y Talend en el backend.
Temario
Tema 1 - Pentaho Data Integration (PDI)
- Características
- Definición y uso de integración de datos
- Licencia
- Ejemplificación de tareas de integración de datos
- Descripción de requerimientos básicos
- Configuración de variables de entorno
- Startup de PDI: Configuración de variables de entorno | Descarga | Instalación | Configuración de Driver JDBC de MySQL
- Scripts de ejecución de Spoon
- Layout de Spoon: Principal | Tabs | Panel Design | Panel View | Accesos rápidos
- Tipos y utilización de Repositorio: Conexión con Repositorio de Pentaho BA | Repositorio en Base de Datos | Repositorio en sistema de archivos | Opción Repository Manager | Metadata
- Principales opciones de la GUI de Spoon: General | Apariencia
- Características y diferencias de Transformations y Jobs
- Práctico: creación de Transformation que genera valores aleatorios
Tema 2 - Transformations, Panel Execution, Panel Execution Results
- Descripción de las características, funcionamiento y comportamiento de las Transformations
- Descripción del Panel Execute, que se despliega antes de ejecutar las Transformations/Jobs: Environment Type | Options |
- Log Level | Parameters | Variables
- Descripción y ejemplificación del Panel Execution Results
- Descripción y análisis de las opciones más importantes de sus Tabs:
- Tab Execution History
- Tab Botón SQL
- Tab Logging
- Tab Step Metrics
- Tab Performance Graph
- Tab Metrics
- Tab Preview data
- Práctico: creación de Transformation que realiza cálculos lógicos y matemáticos
- Práctico: creación de Transformation que analiza los valores del flujo de datos y bifurca el flujo en dos sentidos diferentes; en el primer sentido realizará cálculos y exportará los resultados; en el segundo caso irá a un Step de control
- Práctico: creación de Transformation que obtiene datos de un archivo CSV, los formatea, ordena, concatena y exporta en otro formato
Tema 3 – Variables de Entorno, Parameters, Arguments
- Descripción y uso de las Variables de Entorno
- Ejemplos y notación de las Variables de Entorno
- Descripción y uso de los Parámetros
- Modos de creación de Parámetros
- Descripción, definición y uso de Argumentos
- Descripción y uso de la opción Preview
- Práctico: creación de Transformación cuyos valores obtenidos dependa de los Parámetros asignados en la ejecución
- Práctico: creación de Transformación que obtenga valores de Argumentos, ejecute una función JavaScript y genere un documento HTML
Tema 4 – Expresikones Regulares (RegEx), JavaScript (JS)
- Descripción, aplicación y ejemplos de RegEx
- Documentación y patrones más utilizados de las RegEx
- Aplicación de RegEx en PDI
- Práctico: creación de Transformation que obtenga los nombres de las librerías presentes en PDI y que mediante RegEx separe sintácticamente su nombre, extensión y versión
- Descripción y documentación de JS
- Aplicación de JS en PDI
- Descripción, ejemplificación y aplicación avanzada de Step Modified Java Script Value:
- Transform Scripts
- Transform Constants: SKIP | ERROR | CONTINUE
- Transform Functions
- Input/Output Fields
- Opciones: Position | Compatibility mode | Optimization level
- Configuración de la Grilla Fields para obtener dataset de salida
- Añadir, modificar y configurar distintos tipos de Script: Transform | Start | End
- Práctico: creación de Transformation que obtenga página HTML y realice Web Scrapping utilizando RegEx y JS
Tema 5 – Dataflow
- Práctico: creación de Transfomation que realice las siguientes tareas: análisis, distribución, mapeo, clasificación, aplicación de rangos, aplicación de secuencia condicionada, conversiones
- Manejo del Dataflow:
- Unión básica de Datasets
- Unión de Datasets con diferente Metadata
- Unión de Datasets estableciendo condición de relación
- Unión de Datasets de forma secuencial
- Dividir Dataset entre diversos Steps
- Compartir Dataset completo
- Compartir Dataset de forma distributiva
- Práctico: creación de Transformation que realice las siguientes tareas; convertir de filas a columnas, convertir de columnas a filas, unir Datasets, mapeo y distribución de Datasets, aplicación de fórmulas avanzadas, compartir Dataset
Tema 6 – Variables Globales
- Descripción, uso, ejemplos
- Administración de Variables Globales
- Práctico: creación de Transformation que realice las siguientes tareas: utilizar Variables de Entorno para establecer URL y nombres de archivos; trabajar con datos en formato XML; convertir filas en columnas; comparar dos flujos de datos por aproximación utilizando algoritmo Levenshtein; obtener valores mínimos y máximos; trabajar con datos JSON
Tema 7 – Hops
- Descripción y administración de Hops de Transformations y Jobs
- Configuración avanzada de Hops de Transformations: Habilitar/Deshabilitar | Cambiar dirección | Condición | Borrar | Bulk Change
- Configuración avanzada de Hops de Jobs y análisis de Status: Incondicional | Exito | Fracaso | Habilitar/Deshabilitar
- Descripción de Notas en Transformations/Jobs
- Descripción de las opciones de Grilla
Tema 8 – Share objects
- Descripción y tipos de Objetos Compartidos
- Administración, ejemplificación y utilización de Objetos Compartidos
- Configuración de Metadata de Objetos Compartidos
- Práctico: creación de Transformation que realice las siguientes tareas; obtener diferentes archivos de salida dependiendo de condiciones establecidas en el flujo de datos; comparar flujos de datos identificando elementos nuevos, eliminados y modificados; utilizar Variables de Entorno y RegEx
Tema 9 – Jobs
- Descripción, características y principales usos
- Comportamiento y modo de funcionamiento de los Jobs
- Configuración para ejecución de Steps en paralelo
- Configuración para ejecución de Transformations por cada fila analizada del Dataset
- Análisis y explicación de Ruta de Ejecución de los Steps de Jobs
- Práctico: creación de un Job que realice las siguientes tareas; controle el workflow de ejecución de dos Transformations; evalúe la salida de status de los diferentes Steps
- Práctico: creación de un Job que realice las siguientes tareas; ejecutar una Transformation que genere un Dataset; guardar el Dataset en la lista Result rows; ejecutar una segunda Transformation que obtenga el Dataset de la lista Result rows; configurar salidas de log y analizar los resultados
- Práctico: creación de Transformations y Jobs para ejemplificar las diferentes utilizaciones de Result Filenames
Tema 10 – Result Rows
- Descripción, uso y ejemplificación de Result Rows
Tema 11 – Result Filenames
- Descripción, uso y ejemplificación de Result Filenames
Tema 12 – Variables On The Fly
- Descripción, uso, alcance y ejemplificación de Variables On The Fly
Tema 13 – E-Mail & Web
- Ejemplificación, uso y configuración avanzada de envío de e-mails
- Utilización de diferentes protocolos: POP3 | IMAP | MBOX
- Práctico: creación de Transformations y Jobs que realicen las siguientes tareas; obtener de un archivo CSV una lista de URLs web con los discos de artistas de rock; obtener el documento HTML de cada URL web; filtrar de cada documento HTML la sección dedicada a la lista de canciones de cada disco; generar un archivo CSV por cada disco con la información de sus respectivas canciones.
- Práctico: creación de un Job que realice las siguientes tareas: utilizar Variables de Entorno y RegEx para obtener una lista de archivos; validar direcciones de e-mail; enviar e-mail que contenga como adjuntos los archivos obtenidos
Tema 14 – Steps de Validación en Transformations y Jobs
- Descripción de los principales Steps de Validación en Transformations y Jobs
Tema 15 – Database
- Presentación y restauración de Bases de Datos para realización de práctico
- MySQL:
- Definición y características
- Community Server VS Enterprise Edition
- MySQL Workbench: Características | Instalación | Layout
- Creación de Nueva Instancia
- Explicación de las principales opciones de la Sección Administrativa: Server Status | Client Connections | Users and Privileges | Status and System Variables | Data Export | Data Import/Restore | Startup/Shutdown | Server Logs | Option File
- Explicación de las principales opciones de la Sección SQL: Panel Schemas | Tab Info | Snippets | Log Output | SQL Canvas | Tabs | Accesos rápidos
- Descripción, uso y realización de acciones avanzadas sobre Bases de Datos:
- Obtener Dataset
- Insertar registros
- Actualizar registros
- Borrar registros
- Añadir columna
- Ejecutar Script SQL
- Utilización y configuración avanzada de Error handling
- Definición y utilización de opción Clear Cache Database
- Práctico: creación de Job que realice múltiples tipos de acciones sobre Bases de Datos
Tema 16 – Steps para trabajar con Bases de Datos
- Descripción de principales Steps para trabajar con Bases de Datos
Tema 17 – Data Warehouse
- Creación de Transformation para trabajar con Slowly Changing Dimension (SCD) Tipo 1
- Creación de Transformation para trabajar con Slowly Changing Dimension (SCD) Tipo 2
Tema 18 – Pan & Kitchen
- Descripción de las principales herramientas PDI: Spoon | Pan | Kitchen | Carte
- Opciones avanzadas ejecución de Transformations o Jobs por líneas de comandos
- Parámetros
- Argumentos
- Registro Log
Tema 19 – Scheduling
- Descripción, ejemplificación y uso de Calendarización de ejecución de Transformations y Jobs
- Calendarización utilizando Cron
- Calendarización utilizando Task Scheduler
Tema 20 – Marketplace
- Descripción y características del Marketplace de PDI
- Instalación de plugins: Weka, DataCleaner
Tema 21 – Transformations como Datasource
- Utilización de Transformation como Datasource para Dashboards (CDE)
- Utilización de Transformation como Datasource para Reporting (PRD)
Tema 22 – Transformations como Datasource
- Descripción y características de Pentaho Report Designer (PRD)
- Configuración y ejecución de reportes PRD en Transformation PDI
- Práctico: creación de una Transformation que realice las siguientes tareas: exportar reporte en formato pdf utilizando Parámetros, JS, RegEx y Variables de Entorno; envío de reporte como archivo adjunto en un e-mail
Tema 23 – Lista de Steps de Transformación descritos y utilizados
- Transform | Split Fields
- Transform | Value Mapper
- Transform | Number range
- Transform | Add value fields changing sequence
- Transform | String operations
- Transform | Row flattener
- Transform | Row Normaliser
- Transform | Add constants
- Transform | Calculator
- Transform | Sort rows
- Transform | Concat Fields
- Transform | Add sequence
- Transform | Select values
- Transform | Replace in string
- Transform | Split Fields
- Transform | Value Mapper
- Transform | Number range
- Transform | Add value fields changing sequence
- Transform | String operations
- Transform | Row flattener
- Transform | Row Normaliser
- Flow | Append streams
- Flow | Switch / Case
- Flow | Filter rows
- Flow | Java Filter
- Flow | Dummy
- Flow | Append streams
- Flow | Switch / Case
- Joins | Join Rows
- Job | Copy rows to result
- Job | Get rows from result
- Job | Set files in result
- Job | Get files from result
- Job | Set Variables
- Job | Get Variables
- Utility | Write to log
- Utility | Mail
- Utility | Mail validator
- Utility | If field value is null
- Input | Email messages input
- Input | Table input
- Input | Generate Rows
- Input | Generate random value
- Input | Data Grid
- Input | CSV file input
- Input | Fixed file input
- Input | Get System Info
- Input | GZIP CSV Input
- Input | Get File Names
- Lookup | Table exists
- Lookup | Web Services Lookup
- Lookup | File exists
- Lookup | HTTP Client
- Lookup | Stream lookup
- Lookup | Database lookup
- Lookup | Database join
- Validation | Data Validator
- Output | Table output
- Output | Update
- Output | Insert / Update
- Output | Delete
- Output | Synchronize after merge
- Output | Pentaho Reporting Output
- Output | Text file output
- Output | Microsoft Excel Output
- Data Warehouse | Combination lookup/update
- Data Warehouse | Dimension lookup/update
- Scripting | Execute SQL script
- Scripting | Execute row SQL script
- Scripting | Formula
- Scripting | Modified Java Script Value
Tema 23 – Lista de Steps de Transformación descritos y utilizados
- General | START
- General | Transformation
- General | Success
- General | Job
- Conditions | File Exists
- Conditions | Checks if files exist
- Conditions | Check Db connections
- Conditions | Table exists
- Conditions | Check webservice avaliability
- Conditions | Simple evaluation
- Conditions | Columns exist in a table
- Utility | Abort job
- File management | Add filenames to result
- Mail | Mail validator
- Mail | Mail
- Scripting | SQL
Contacto
Ajustamos cada curso a sus necesidades.
Nuestra oficina en Madrid
- Avenida de Brasil 17. Planta 16
- 28046 Madrid
- info@stratebi.com
- Tlfno: +34 91.788.34.10
- Fax:+34 91.788.57.01