


Before organising a course or seminar, we listen to the real needs and objectives of each client, in order to adapt the training and get the most out of it. We tailor each course to your needs.
We are also specialists in 'in company' trainings adapted to the needs of each organisation, where the benefit for several attendees from the same company is much greater. If this is your case, contact us.
Ponemos a disposición también plataforma Cloud con todas las herramientas instaladas y configuradas, listas para la formación, incluyendo ejercicios, bases de datos, etc... para no perder tiempo en la preparación y configuración inicial. ¡Sólo preocuparos de aprender!
Ofrecemos también la posibilidad de realizar formaciones en base a ‘Casos de Uso’
Se complementa la formación tradicional de un temario/horas/profesor con la realización de casos prácticos en las semanas posteriores al curso en base a datos reales de la propia organización, de forma que se puedan ir poniendo en producción proyectos iniciales con nuestro soporte, apoyo al desarrollo y revisión con los alumnos y equipos, etc…
En los 10 últimos años, ¡hemos formado a más de 250 organizaciones y 3.000 alumnos!
Ah, y regalamos nuestras famosas camisetas de Data Ninjas a todos los asistentes. No te quedes si las tuyas





Curso de Pentaho Data Integration – Extracción, Transformación y Carga de Datos
Curso de Pentaho Data Integration – Extracción, Transformación y Carga de Datos
Goal
Incluye: Material de estudio, ejercicios prácticos, acceso a infraestructura cloud y certificación oficial.
Aprende a extraer, transformar y cargar datos con una de las herramientas ETL más potentes del mercado, optimizando flujos de datos y automatizando procesos empresariales.
La extracción, transformación y carga (ETL) de los datos es la clave del éxito en un sistema BI, que permite gestionar la calidad de los datos de forma adecuada.
En este curso te contaremos algunas de las mejores prácticas que recomendamos durante el diseño de los procesos ETL como:
Centralización de los procedimientos, de forma que se asegure la coherencia y homogeneidad de los datos intercambiados desde las distintas fuentes.
Evitar la redundancia de cálculos: si existe el dato previamente calculado en las bases de datos operacionales, no debe volver a realizarse el cálculo en la extracción. Esta premisa pretende conseguir un doble objetivo.
Establecimiento de puntos de "control de calidad" y validación.
Implementar procesos de recarga de la información, ante posibles errores en la información inicial.
Contemplar la posibilidad de utilizar tablas intermedias con el nivel más atómico de la información a tratar.
Además, repasaremos los elementos más importantes y usados de la herramienta de ETLs de Pentaho: Kettle o Pentaho Data Integration.
Accede a nuestra DEMO BI Completa

Compruebe el potencial de nuestras soluciones
En Stratebi hemos creado un gran número de Demos Online, para que pueda ver algunos ejemplos realizados para varios sectores, con datos públicos. Descubra de forma práctica la cantidad de posibilidades que ofrecen nuestras soluciones y desarrollos.
En la demo, podrá evaluar las herramientas LinceBI (STPivot, STDashboard o STCard), un conjunto de herramientas desarrolladas por Stratebi y que dotan de gran potencia a nuestras soluciones.
Solicite una clave de acceso Accede a la Demo BI
Target audiences
Observations
Data Quality e integración con Pentaho
Novedades Pentaho Data Integration 9.0
Las principales novedades de PDI 9.0 son las siguientes:
- Los usuarios pueden acceder y procesar datos de múltiples clústeres de Hadoop, de diferentes distribuciones y versiones, todo desde una sola transformación e instancia de Pentaho.
- Además, dentro de Spoon, los usuarios ahora pueden configurar tres configuraciones distintas de clúster, todas con referencia a un clúster específico, sin tener que reiniciar Spoon.
- La nueva interfaz de usuario brinda una experiencia mejorada para la configuración de clústeres y para la creación de conexiones seguras.
- Admite las siguientes distribuciones: Hortonworks HDP v3.0, 3.1; Cloudera CDH v6.1, 6.2; Amazon EMR v5.21, 5.24.
El siguiente ejemplo muestra un Multi-clúster implementado sobre el mismo pipeline de datos con conexión a los clústeres Hortonworks HDP y Cloudera CDH. 
Casos de uso y beneficios
· Permite el procesamiento de Big Data híbrido (local o en la nube), dentro de un mismo pipeline de procesamiento de datos.
· Simplifica la integración de Pentaho con clústeres de Hadoop, mediante una experiencia de usuario mejorada para configuraciones de clúster.
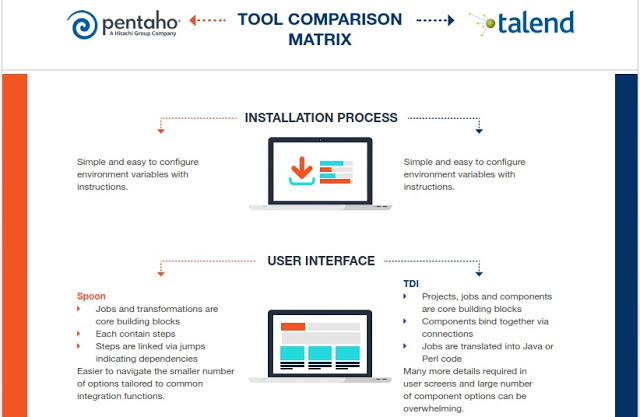
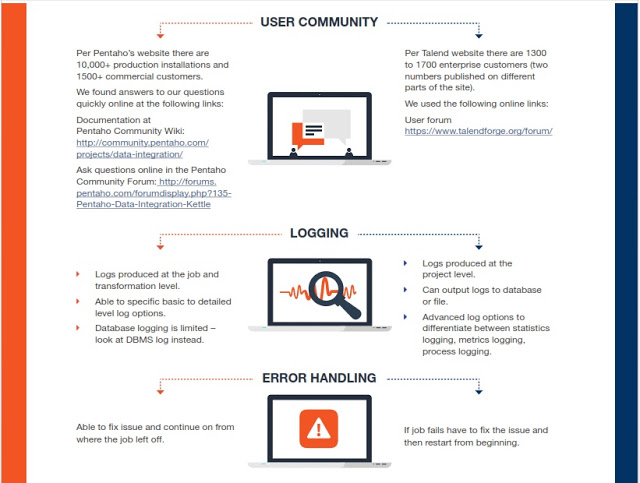
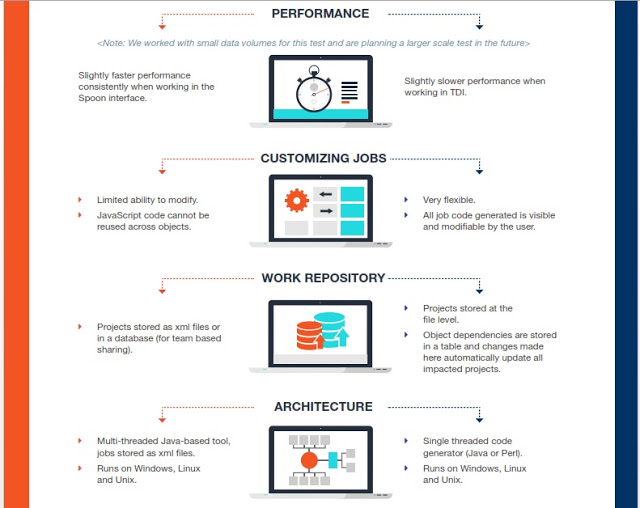
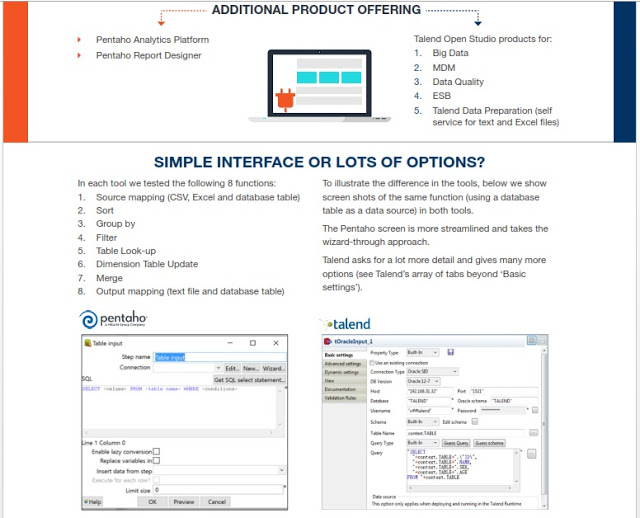
Comparativa Kettle (Pentaho Data Integration) y Talend
Tanto Kettle como Talend son grandes herramientas, muy visuales, que nos permiten integrar todo tipo de fuentes, incluyendo también Big Data para hacer todo tipo de transformaciones y proyectos de integración o para preparar potentes entornos analíticos, también con soluciones Open Source como podéis ver en esta Demo Online , donde se han usado Kettle y Talend en el backend.
Syllabus
- Introducción a los procesos ETL y su importancia en Business Intelligence.
- ¿Qué es Pentaho Data Integration (PDI) y cómo se usa?
- Instalación y configuración de PDI en distintos entornos.
- Herramientas clave de PDI: Spoon, Pan, Kitchen y Carte.
- Diferencias entre Transformations y Jobs y cuándo usarlas.
- Configuración de variables de entorno y gestión de parámetros.
- Uso de repositorios en PDI: archivos locales vs. bases de datos.
- Conexión con bases de datos mediante JDBC y JNDI.
- Ejercicio práctico: creación de una transformación básica en Spoon.
- Tipos de fuentes de datos en procesos ETL: estructurados y no estructurados.
- Importación de datos desde archivos CSV, Excel, JSON y XML.
- Conexión con bases de datos relacionales (MySQL, PostgreSQL, SQL Server).
- Integración con APIs REST y servicios web para la extracción de datos.
- Uso de Pentaho Data Services para consultas dinámicas.
- Extracción en tiempo real desde Kafka y sistemas en streaming.
- Conexión con sistemas NoSQL (MongoDB, Cassandra, Hadoop, Spark).
- Estrategias de optimización en la extracción de datos.
- Ejercicio práctico: integración de múltiples fuentes de datos en un solo flujo.
- Normalización y estandarización de datos en PDI.
- Aplicación de reglas de negocio en transformaciones de datos.
- Manejo de datos faltantes, duplicados y valores nulos.
- Uso de los pasos de transformación en Spoon: Filter, Join, Split, Replace.
- Validación de datos mediante Expresiones Regulares (RegEx).
- Transformaciones avanzadas con JavaScript y fórmulas.
- Implementación de cálculos y agregaciones en PDI.
- Auditoría de datos y estrategias de control de calidad.
- Ejercicio práctico: limpieza y transformación de un dataset con errores.
- Tipos de almacenamiento de datos: relacional, NoSQL y Data Warehousing.
- Inserción, actualización y eliminación de datos en bases de datos SQL.
- Uso de Bulk Loading para optimizar cargas masivas de datos.
- Estrategias de particionamiento y almacenamiento eficiente.
- Implementación de Slowly Changing Dimensions (SCD) en PDI.
- Exportación de datos a diferentes formatos: CSV, JSON, XML, Parquet.
- Integración con Data Lakes y arquitecturas modernas.
- Optimización del rendimiento en cargas ETL a gran escala.
- Ejercicio práctico: carga de datos optimizada en una base de datos.
- Uso de Jobs en PDI para la ejecución de flujos de datos.
- Planificación y calendarización de procesos con Pentaho Scheduler.
- Integración con herramientas de automatización: Airflow, Jenkins, Crontab.
- Configuración de alertas y monitoreo de errores en ETL.
- Control de flujo con condiciones, loops y variables dinámicas.
- Procesamiento en paralelo para mejorar el rendimiento de ETL.
- Integración de Pentaho con Apache Kafka y procesamiento en streaming.
- Orquestación de flujos en entornos cloud y distribuidos.
- Ejercicio práctico: creación de un flujo ETL automatizado con Jobs.
- Administración de usuarios y permisos en Pentaho BI Server.
- Configuración de entornos de desarrollo, prueba y producción.
- Implementación de logs y auditoría en procesos ETL.
- Control de versiones en Git para flujos ETL.
- Estrategias de recuperación ante errores y fallos en ETL.
- Mantenimiento y optimización de procesos ETL en producción.
- Integración de PDI con entornos Cloud (AWS, Azure, GCP).
- Mejores prácticas en el desarrollo de procesos ETL escalables.
- Ejercicio práctico: implementación de seguridad y logs en un flujo ETL.
- Definición del caso de estudio: aplicación real en ETL.
- Diseño de la arquitectura del proyecto: herramientas y modelos.
- Implementación de procesos de extracción con Pentaho PDI.
- Transformación y limpieza de datos según requerimientos de negocio.
- Carga de datos optimizada en bases de datos SQL y Data Warehouses.
- Automatización y monitoreo del flujo ETL.
- Optimización y escalabilidad del sistema ETL.
- Presentación del proyecto final y validación de resultados.
- Conclusiones, mejores prácticas y certificación del curso.
Curso de Business Intelligence y Data Warehousing con Pentaho
Curso de Business Intelligence y Data Warehousing con Pentaho
Goal
Incluye: Material de estudio, ejercicios prácticos, acceso a infraestructura cloud y certificación oficial.
Accede a nuestra DEMO BI Completa
Compruebe el potencial de nuestras soluciones
En Stratebi hemos creado un gran número de Demos Online, para que pueda ver algunos ejemplos realizados para varios sectores, con datos públicos. Descubra de forma práctica la cantidad de posibilidades que ofrecen nuestras soluciones y desarrollos.
En la demo, podrá evaluar las herramientas LinceBI (STPivot, STDashboard o STCard), un conjunto de herramientas desarrolladas por Stratebi y que dotan de gran potencia a nuestras soluciones.
Solicite una clave de acceso Accede a la Demo BI
Target audiences
Syllabus
- Introducción a BI: importancia y beneficios en la toma de decisiones.
- Evolución del BI: de los sistemas DSS y EIS a las soluciones modernas.
- Procesos clave en BI: análisis, integración, transformación y visualización.
- Conceptos fundamentales de Data Warehousing (DWH) y su aplicación.
- Diferencias entre Data Warehouse (DW) y Data Marts.
- Modelos de datos en BI: Star Schema, Snowflake y Starflake.
- Estrategias de implementación de DW: enfoque Top-Down vs. Bottom-Up.
- Herramientas Open Source en BI: ventajas del software libre en análisis de datos.
- Introducción a Pentaho Data Integration (PDI): funciones y características.
- Instalación y configuración de PDI: herramientas clave (Spoon, Kitchen, Pan, Carte).
- Creación de procesos ETL: extracción, transformación y carga de datos.
- Conexión y manejo de bases de datos con JDBC en Pentaho.
- Modelado y transformación de datos: uso de repositorios y metadatos.
- Ejercicios prácticos: carga de un Data Warehouse con dimensiones y hechos.
- Configuración de variables en Spoon para entornos dinámicos.
- Estrategias de depuración y optimización de flujos ETL en PDI.
- Introducción a Mondrian y modelado OLAP en Pentaho.
- Capas de Mondrian: presentación, dimensional, estrella y almacenamiento.
- Diseño y creación de cubos OLAP en Pentaho Schema Workbench (PSW).
- Definición de dimensiones, jerarquías y niveles para análisis de datos.
- Creación y optimización de medidas y métricas de negocio.
- Consultas avanzadas con MDX (Multidimensional Expressions). Uso de STPivot.
- Ejercicios prácticos de modelado de cubos y consultas multidimensionales.
- Integración de modelos OLAP con herramientas de reporting y dashboards.
- Introducción a MySQL como base de datos para Business Intelligence.
- Instalación y configuración de MySQL Workbench.
- Gestión y optimización de bases de datos relacionales en BI.
- Uso de JDBC para la conexión entre Pentaho y MySQL.
- Administración de consultas SQL en entornos analíticos.
- Seguridad y buenas prácticas en la gestión de bases de datos.
- Integración de MySQL con herramientas de procesamiento de datos.
- Ejercicios prácticos sobre modelado y consulta de datos en MySQL.
- Instalación y configuración de Pentaho Business Analytics.
- Uso de Pentaho User Console (PUC) para gestión de reportes.
- Creación de informes dinámicos y análisis en tiempo real.
- Uso de herramientas avanzadas como STReport y STDashboard.
- Personalización de dashboards con gráficos y visualizaciones interactivas.
- Diseño de reportes OLAP con análisis Drill-down y Pivot.
- Publicación de informes y distribución en entornos empresariales.
- Optimización del rendimiento y estrategias de visualización de datos.
- Introducción a Pentaho Aggregation Designer
- Creación y gestión de agregaciones de datos para mejorar el rendimiento.
- Modelado de bases de datos multidimensionales optimizadas.
- Generación de estructuras preagregadas para consultas rápidas.
- Publicación y actualización de esquemas optimizados.
- Configuración avanzada de fuentes de datos en Pentaho BI Server.
- Técnicas de mejora en tiempos de respuesta de reportes OLAP.
- Casos prácticos de optimización en entornos empresariales.
- Definición del caso de estudio: aplicación real en BI.
- Diseño de la arquitectura del proyecto: integración de herramientas y datos.
- Implementación del proceso ETL con Pentaho PDI.
- Modelado y análisis de datos con Pentaho Schema Workbench.
- Creación de dashboards y reportes con Pentaho y LinceBI.
- Optimización y escalabilidad del sistema BI.
- Presentación del proyecto final con validación de resultados.
- Conclusiones, mejores prácticas y certificación.
ETLs WITH TALEND
ETLs WITH TALEND
Goal
Talend is the European leader in data integration (ETL), Data Quality and Master Data Management.
It is backed by the creators and founders of Business Objects.
We are one of the first specialists in Talend in Spain.
Tibco did migration to Talend for Yell. We provide practical training, which lays the foundation of the Business Intelligence strategy, accompanied by participatory sessions, on real cases and business solutions.
Target audiences
Observations
Certification
All students receiving the course will be given a certificate of attendance.
Syllabus
1. Introduction
- Environments operations and integration with Business Intelligence
- Initial presentation of Talend Open Studio
2. Modeling jobs
- Using the Business Modeler
- Document management for the project
3. Using Job Designer to generate code
- Examples and exercises work designs
- Testing data sets
4. Components input / output
- Management access to XML files, delimited characters, etc ...
- Access Relational Databases
5. Metadata Repository
- Centralize connections
- Centralizing data flows and schemes
6. Data Transformations
- Using different components transformations
- Parameterization and mapping data using TMAP (join)
- Profiling data using filters
- Generation of different outputs and exception handling
- Practical exercises
7. Development Features
- Defining project environments (development, production)
- Inclusion of java code on jobs
- Set error handling
- Get statistics and logs of work
8. Debug and Deploy jobs
- Generation of technical documentation of work
- Using the Debug view
- Generate jobs and provide them as Web services
Machine Learning
Machine Learning
Goal
This course will understand the concepts needed to perform processes Machine Learning, this branch of artificial intelligence that aims to develop techniques that allow computers to learn.
Machine Learning projects create algorithms that can generalize and recognize behavior patterns from information provided by way of example ( training). Machine Learning techniques are used among others in the following areas: Medicine, Bioinformatics, Marketing, Natural Language Processing, Image Processing, Machine Vision, Spam Detection.

Target audiences
- ICT professionals: Consultants BI, Scientific Data.
- Professionals of Applied Sciences: Mathematics, Statistics, Physics.
Observations
- Methodology: The course intersperses theoretical parts where fundamental concepts are taught to understand the practical exercises taught.
- Requirements: Basics: Linear Algebra, calculus and probability theory.

Syllabus
Machine Learning with Scikit-Learn Data Science framework (Anaconda with Python 3)
1. Introduction to Machine Learning
- Techniques
- Classification
- Regression
- Clustering
- Preprocessing and dimensional reduction
- Attribute selection
- Performance evaluation
- Matrices de confusión
- KPIs R2, MAE, MSE
2. Regression (Prediction of continuous values)
- Algorithms
- Ordinal Least Squares
- Ridge Regression
- Laso Regression
- Elastic Net
- Examples
3. Classification (Identification of the category to which an object belongs)
- Algorithms
- Logistic Regression
- Support Vector Machines
- KNearest Neighbors
- Decision Trees
- Random Forest
- Multi-layer Perceptron
- Examples
4. Clustering (Grouping similar objects in sets)
- Algorithms
- KMeans
- Spectral Clustering
- DBSCAN
- Examples
Contacto
Ajustamos cada curso a sus necesidades.
Nuestra oficina en Madrid
- Avenida de Brasil 17. Planta 16
- 28046 Madrid
- info@stratebi.com
- Tlfno: +34 91.788.34.10
- Fax:+34 91.788.57.01