


Antes de realizar un curso o seminario, escuchamos las necesidades reales y objetivos de cada cliente, para adecuar la formación y obtener el mayor aprovechamiento posible. Ajustamos cada curso a sus necesidades.
Somos también especialistas en formaciones 'in company' adaptadas a las necesidades de cada organización, donde el aprovechamiento para varios asistentes de la misma compañía es mucho mayor. Si es tu caso, contacta con nosotros.
Ponemos a disposición también plataforma Cloud con todas las herramientas instaladas y configuradas, listas para la formación, incluyendo ejercicios, bases de datos, etc... para no perder tiempo en la preparación y configuración inicial. ¡Sólo preocuparos de aprender!
Ofrecemos también la posibilidad de realizar formaciones en base a ‘Casos de Uso’
Se complementa la formación tradicional de un temario/horas/profesor con la realización de casos prácticos en las semanas posteriores al curso en base a datos reales de la propia organización, de forma que se puedan ir poniendo en producción proyectos iniciales con nuestro soporte, apoyo al desarrollo y revisión con los alumnos y equipos, etc…
En los 10 últimos años, ¡hemos formado a más de 250 organizaciones y 3.000 alumnos!
Ah, y regalamos nuestras famosas camisetas de Data Ninjas a todos los asistentes. No te quedes si las tuyas





Curso de Cloud Analytics
Curso de Cloud Analytics
Objetivo
Aprenda a tomar la decisión correcta para tu próximo proyecto basado en tecnologías Cloud.
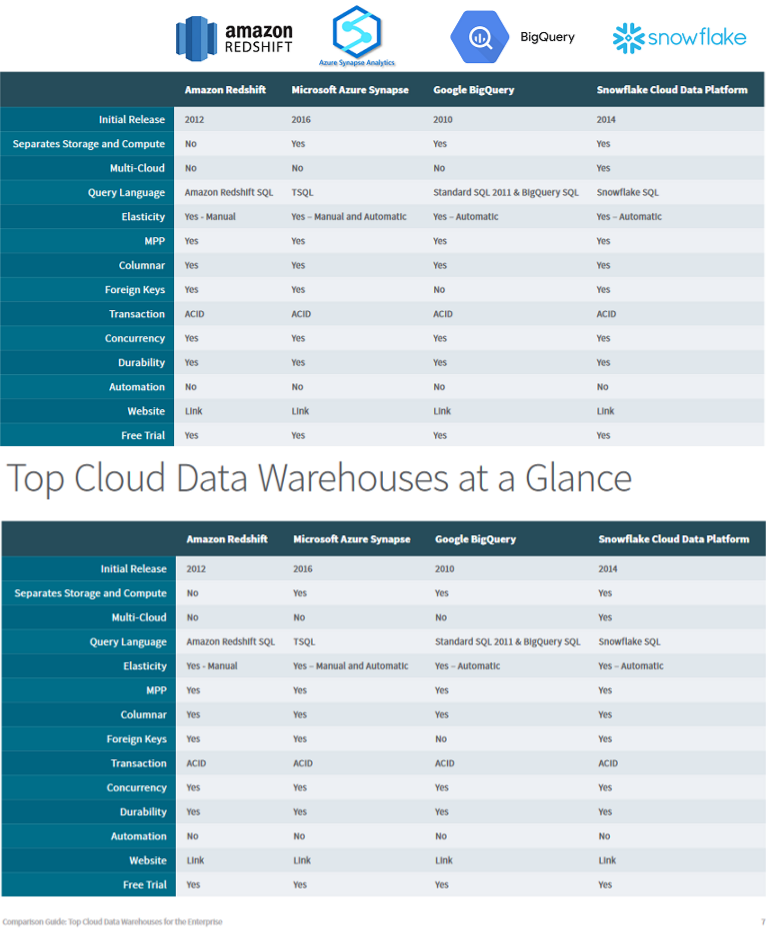
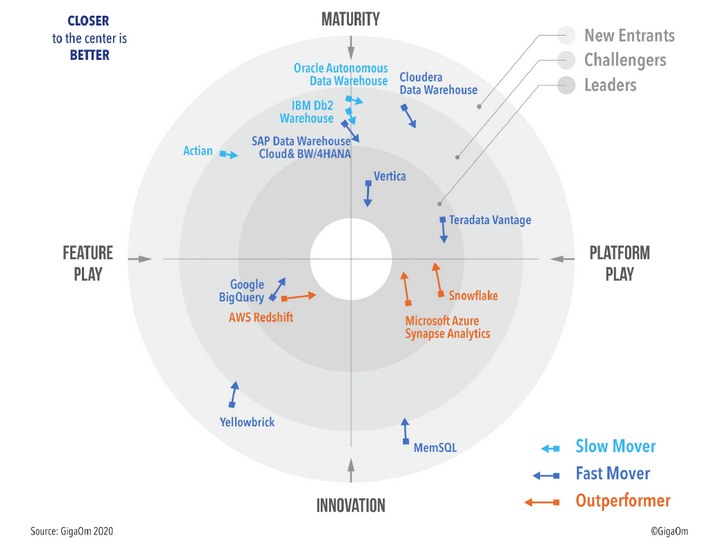
¿Cuál proveedor Cloud usar en tu arquitectura Big Data? Conozca a los servicios que te permitirán ahorrar tiempo y recursos en tus proyectos Data Driven. Veremos en ese curso herramientas de proovedores como AWS, GCP, Azure, Snowflake, y otras.
Público objetivo
Temario
Explorar las opciones de computación y almacenamiento para cargas de trabajo de ingeniería de datos
- Introducción a Azure Synapse Analytics
- Describir Azure Databricks
- Introducción al almacenamiento de Azure Data Lake
- Describir la arquitectura de Delta Lake
- Trabajar con flujos de datos mediante Azure Stream Analytics
- Combinar la transmisión y el procesamiento por lotes con una única pipeline
- Organizar el data lake en niveles de transformación de archivos
- Indexación de almacenamiento de data lake para la aceleración de consultas y cargas de trabajo
Diseño e implementación de la capa de servicio
- Diseñar un esquema multidimensional para optimizar las cargas de trabajo analíticas
- Transformación sin código a escala con Azure Data Factory
- Rellenar dimensiones que cambian lentamente en las pipelines de Azure Synapse Analytics
- Diseñar un esquema en estrella para cargas de trabajo analíticas
- Rellenar dimensiones que cambian lentamente con Azure Data Factory y mapeo de flujos de datos
Consideraciones de ingeniería de datos para archivos fuente
- Diseñar un almacén de datos moderno con Azure Synapse Analytics
- Proteger un almacén de datos en Azure Synapse Analytics
- Administrar archivos en un data lake de Azure
- Protección de archivos almacenados en un data lake de Azure
Ejecutar consultas interactivas con grupos de SQL sin servidor de Azure Synapse Analytics
- Explorar las capacidades de los grupos SQL sin servidor de Azure Synapse
- Consultar datos en el lake mediante grupos de SQL sin servidor de Azure Synapse
- Crear objetos de metadatos en grupos SQL sin servidor de Azure Synapse
- Proteger los datos y administrar a los usuarios en los grupos SQL sin servidor de Azure Synapse
- Consultar datos de Parquet con grupos SQL sin servidor
- Crear tablas externas para archivos Parquet y CSV
- Crear vistas con grupos de SQL sin servidor
- Acceso seguro a los datos en un data lake cuando se utilizan grupos de SQL sin servidor
- Configurar la seguridad del data lake mediante el control de acceso basado en roles (RBAC) y la lista de control de acceso
Explorar, transformar y cargar datos en el almacén de datos usando Apache Spark
- Comprender la ingeniería de big data con Apache Spark en Azure Synapse Analytics
- Ingestar datos con los cuadernos de Apache Spark en Azure Synapse Analytics
- Transformar datos con DataFrames en Apache Spark Pools en Azure Synapse Analytics
- Integrar grupos de SQL y Apache Spark en Azure Synapse Analytics
- Realizar exploración de datos en Synapse Studio
- Ingestar datos con cuadernos Spark en Azure Synapse Analytics
- Transformar datos con DataFrames en grupos de Spark en Azure Synapse Analytics
- Integrar grupos de SQL y Spark en Azure Synapse Analytics
Exploración y transformación de datos en Azure Databricks
- Describir Azure Databricks
- Leer y escribir datos en Azure Databricks
- Trabajar con DataFrames en Azure Databricks
- Trabajar con métodos avanzados de DataFrames en Azure Databricks
- Usar DataFrames en Azure Databricks para explorar y filtrar datos
- Almacenar en caché un DataFrame para consultas posteriores más rápidas
- Eliminar datos duplicados
- Manipular valores de fecha / hora
- Eliminar y cambiar el nombre de las columnas DataFrame
- Agregar datos almacenados en un DataFrame
Ingesta y carga datos en el almacén de datos.
- Utilizar las mejores prácticas de carga de datos en Azure Synapse Analytics
- Ingestión a escala de petabytes con Azure Data Factory
- Realizar la ingestión a escala de petabytes con Azure Synapse Pipelines
- Importar datos con PolyBase y COPY usando T-SQL
- Utilizar las mejores prácticas de carga de datos en Azure Synapse Analytics
Transformar datos con Azure Data Factory o Azure Synapse Pipelines
- Integración de datos con Azure Data Factory o Azure Synapse Pipelines
- Transformación sin código a escala con Azure Data Factory o Azure Synapse Pipelines
- Ejecutar transformaciones sin código a escala con Azure Synapse Pipelines
- Crear un pipeline de datos para importar archivos CSV con formato deficiente
- Crear flujos de datos de mapeo
Orquestar el movimiento y la transformación de datos en Azure Synapse Pipelines
- Organizar el movimiento y la transformación de datos en Azure Data Factory
- Integrar datos de portátiles con Azure Data Factory o Azure Synapse Pipelines
Optimizar el rendimiento de las consultas con grupos de SQL dedicados en Azure Synapse
- Optimizar el rendimiento de las consultas del almacén de datos en Azure Synapse Analytics
- Comprender las características para desarrolladores de almacenamiento de datos de Azure Synapse Analytics
- Comprender las características para desarrolladores de Azure Synapse Analytics
- Optimizar el rendimiento de las consultas del almacén de datos en Azure Synapse Analytics
- Mejorar el rendimiento de las consultas
Analizar y optimizar el almacenamiento del data wharehouse
- Analizar y optimizar el almacenamiento del data wharehouse de datos en Azure Synapse Analytics
- Comprobar si hay datos sesgados y uso de espacio
- Comprender los detalles de almacenamiento de la tienda de columnas
- Estudiar el impacto de las vistas materializadas
- Explorar las reglas para operaciones mínimamente registradas
Soporte del procesamiento analítico transaccional híbrido (HTAP) con Azure Synapse Link
- Diseñar procesamiento transaccional y analítico híbrido con Azure Synapse Analytics
- Configurar Azure Synapse Link con Azure Cosmos DB
- Consultar Azure Cosmos DB con grupos de Apache Spark
- Consultar Azure Cosmos DB con grupos de SQL sin servidor
- Configurar Azure Synapse Link con Azure Cosmos DB
- Consultar Azure Cosmos DB con Apache Spark para Synapse Analytics
- Consultar Azure Cosmos DB con un grupo de SQL sin servidor para Azure Synapse Analytics
Seguridad de un extremo a otro con Azure Synapse Analytics
- Proteger un almacén de datos en Azure Synapse Analytics
- Configurar y administrar secretos en Azure Key Vault
- Implementar controles de cumplimiento para datos confidenciales
- Asegurar la infraestructura de soporte de Azure Synapse Analytics
- Asegurar el área de trabajo de Azure Synapse Analytics y los servicios administrados
- Proteger los datos del área de trabajo de Azure Synapse Analytics
Procesamiento de transmisión en tiempo real con Stream Analytics
- Habilitar la mensajería confiable para aplicaciones de Big Data con Azure Event Hubs
- Trabajar con flujos de datos mediante Azure Stream Analytics
- Ingesta flujos de datos con Azure Stream Analytics
- Utilizar Stream Analytics para procesar datos en tiempo real de Event Hubs
- Utilizar las funciones de ventana de Stream Analytics para crear agregados y resultados en Synapse Analytics
- Escalar el trabajo de Azure Stream Analytics para aumentar el rendimiento mediante la partición
- Repartir la entrada de flujo para optimizar la paralelización
Crear una solución de procesamiento de transmisión con Event Hubs y Azure Databricks
- Procesar datos de streaming con transmisión estructurada de Azure Databricks
- Explorar las características y usos clave de la transmisión estructurada
- Transmitir datos desde un archivo y escríbirlos en un sistema de archivos distribuido
- Utilizar ventanas deslizantes para agregar fragmentos de datos en lugar de todos los datos
- Aplicar marcas de agua para eliminar datos obsoletos
- Conectarse a transmisiones de lectura y escritura de Event Hubs
Generar informes mediante la integración de Power BI con Azure Synpase Analytics
- Crear informes con Power BI utilizando su integración con Azure Synapse Analytics
- Integrar un área de trabajo de Azure Synapse y Power BI
- Optimizar la integración con Power BI
- Mejorar el rendimiento de las consultas con vistas materializadas y almacenamiento en caché de conjuntos de resultados
- Visualizar datos con SQL sin servidor y crear un informe de Power BI
Realizar procesos integrados de aprendizaje automático en Azure Synapse Analytics
- Utilizar el proceso de aprendizaje automático integrado en Azure Synapse Analytics
- Crear un servicio vinculado de Azure Machine Learning
- Activar un experimento de Auto ML con datos de una tabla Spark
- Enriquecer los datos utilizando modelos entrenados
- Ofrecer resultados de predicción con Power BI
Fundamentos
- Qué es cloud computing.
- Diferentes tipos de cloud computing.
- Modelos básicos en la nube.
- Componentes de la nube.
- Hardware Cloud.
- Virtualización.
- Cloud storage.
- Grid Computing.
- Computing transaccional.
- Software Cloud
- SaaS.
- Disponibilidad On-Demand.
- Pago por uso.
- SOA y la nube.
- Modelos de nubes.
- Seguridad, Auditoria y Cumplimiento en la Nube.
- Plataformas varias.
Amazon Elastic MapReduce - EMR
- Información general acerca de los grandes datos y Apache Hadoop.
- Soluciones AWS en un ecosistema Bigdata.
- Beneficios de Amazon EMR.
- Arquitectura de Amazon EMR. Utilización de Amazon EMR.
- Inicio y utilización y configuracion de un clúster de Amazon EMR.
- Marcos de programación de alto nivel de Apache Hadoop.
- Marcos de Programacion para Amazon EMR: Hive.
- Pig Streaming.
- Utilización de Hive para análisis promocionales.
- Hue para Anazon EMR.
- Analisis integrados en memoria con SPARK en Amazon EMR.
- Otros marcos de programación de Apache Hadoop.
- Utilización de Streaming para análisis sobre las ciencias de la vida.
- Gestión de costes de Amazon EMR.
- Información general acerca de la seguridad de Amazon EMR.
- Análisis de seguridad de Amazon EMR.
- Procesamiento, transferencia y compresión de datos.
Amazon Warehouse - Amazon RedShift
- Opciones de almacenamiento de datos de AWS.
- Utilización de DynamoDB con Amazon EMR.
- Información general acerca de Amazon Redshift y los grandes datos.
- Utilización de Amazon Redshift para grandes datos Visualización y orquestación de grandes datos.
- Utilización de Tableau Desktop o de la inteligencia empresarial de Jaspersoft para visualizar grandes datos.
- Recursos y componentes de Amazon Redshift.
- Lanzamiento de un clúster de Amazon Redshift.
- Revisión de las estrategias de almacenamiento de datos.
- Identificación de requisitos y orígenes de datos.
- Diseño de almacén de datos.
- Carga de datos en el almacén de datos.
- Escritura de consultas y ajuste de rendimiento.
- Mantenimiento del almacén de datos.
- Análisis y visualización de datos.
Real time streaming data - Amazon Kinesis
- Transmision Datos en tiempo real.
- Kinesis Data Analytics.
- Amazon Kinesis Data Firehos; registrar, transformar y cargar
transmisiones de datos en almacenes de datos de AWS para realizar análisis en tiempo real con herramientas de inteligencia empresarial existentes. - Amazon Kinesis Data Streams: Crear aplicaciones personalizadas en tiempo real que procesen transmisiones de datos con marcos de procesamiento de transmisiones conocidos.
- Amazon Kinesis Video Streams: Transmisión segura de videos desde dispositivos conectados a AWS para análisis, aprendizaje automático y otros procesos.
- Amazon DynamoDB, Amazon Quicksight, Amazon Athena.
- SnowPro™ Core Certification Overview
- Snowflake Overview and Architecture
- Snowflake Virtual Warehouses
- Snowflake Storage and Protection
- Data Movement (Loading and Unloading)
- Snowflake Account and Security
- Snowflake Performance and Tuning
Contacto
Ajustamos cada curso a sus necesidades.
Nuestra oficina en Madrid
- Avenida de Brasil 17. Planta 16
- 28046 Madrid
- info@stratebi.com
- Tlfno: +34 91.788.34.10
- Fax:+34 91.788.57.01