


Antes de realizar un curso o seminario, escuchamos las necesidades reales y objetivos de cada cliente, para adecuar la formación y obtener el mayor aprovechamiento posible. Ajustamos cada curso a sus necesidades.
Somos también especialistas en formaciones 'in company' adaptadas a las necesidades de cada organización, donde el aprovechamiento para varios asistentes de la misma compañía es mucho mayor. Si es tu caso, contacta con nosotros.
Ponemos a disposición también plataforma Cloud con todas las herramientas instaladas y configuradas, listas para la formación, incluyendo ejercicios, bases de datos, etc... para no perder tiempo en la preparación y configuración inicial. ¡Sólo preocuparos de aprender!
Ofrecemos también la posibilidad de realizar formaciones en base a ‘Casos de Uso’
Se complementa la formación tradicional de un temario/horas/profesor con la realización de casos prácticos en las semanas posteriores al curso en base a datos reales de la propia organización, de forma que se puedan ir poniendo en producción proyectos iniciales con nuestro soporte, apoyo al desarrollo y revisión con los alumnos y equipos, etc…
En los 10 últimos años, ¡hemos formado a más de 250 organizaciones y 3.000 alumnos!
Ah, y regalamos nuestras famosas camisetas de Data Ninjas a todos los asistentes. No te quedes si las tuyas





Curso de Azure Databricks
Curso de Azure Databricks
Objetivo
Somos partners oficiales de Microsoft
Análisis de macrodatos e inteligencia artificial con Apache Spark optimizado.
Obtenga conclusiones a partir de todos sus datos y cree soluciones de inteligencia artificial (IA) con Azure Databricks, configure un entorno de Apache Spark™ en solo unos minutos, aplique escalabilidad automática y colabore en proyectos compartidos en un área de trabajo interactiva. Azure Databricks admite Python, Scala, R, Java y SQL, además de marcos y bibliotecas de ciencia de datos, como TensorFlow, PyTorch y scikit-learn.
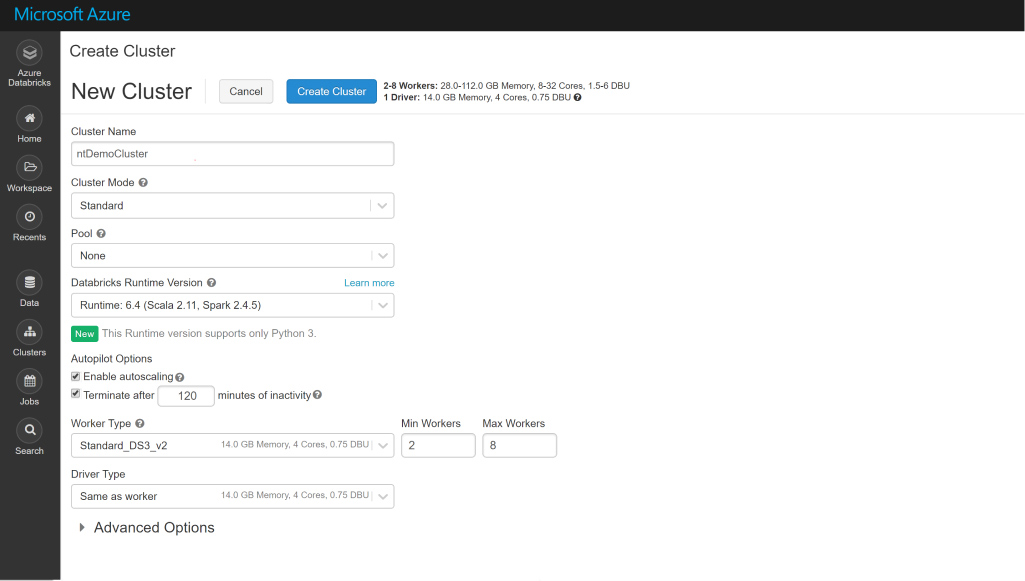
Póngase en marcha rápidamente con un entorno de Apache Spark optimizado.
Azure Databricks proporciona las últimas versiones de Apache Spark y permite la integración sin problemas con bibliotecas de código abierto. Ponga en marcha clústeres y cree soluciones con rapidez en un entorno de Apache Spark totalmente administrado, con la escala global y la disponibilidad de Azure. Los clústeres se instalan, configuran y ajustan para asegurar la confiabilidad y el rendimiento sin necesidad de supervisión. Aproveche la escalabilidad y la terminación automáticas para mejorar el costo total de propiedad (TCO).
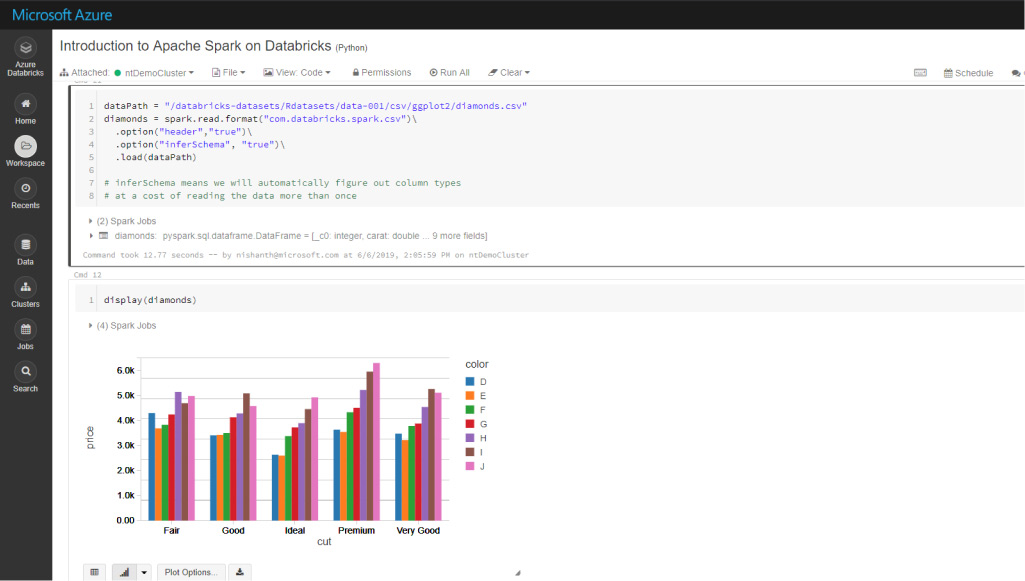
Aumente el potencial del aprendizaje automático con macrodatos.
Acceda a funcionalidad de aprendizaje automático avanzado y automatizado con el servicio integrado Azure Machine Learning para identificar con rapidez los algoritmos e hiperparámetros adecuados. Simplifique la administración, la supervisión y la actualización de los modelos de Machine Learning implementados desde la nube hasta el perímetro. Azure Machine Learning proporciona también un registro central de sus experimentos, modelos y canalizaciones de aprendizaje automático.

Obtenga un almacenamiento de datos moderno de alto rendimiento.
Combine datos a cualquier escala y extraiga información a través de paneles analíticos e informes operativos. Automatice el movimiento de los datos con Azure Data Factory; después, cargue los datos en Azure Data Lake Storage, transfórmelos y límpielos con Azure Databricks y déjelos disponibles para analizarlos con Azure Synapse Analytics. Modernice su almacenamiento de datos en la nube para conseguir unos niveles inigualables de rendimiento y escalabilidad.
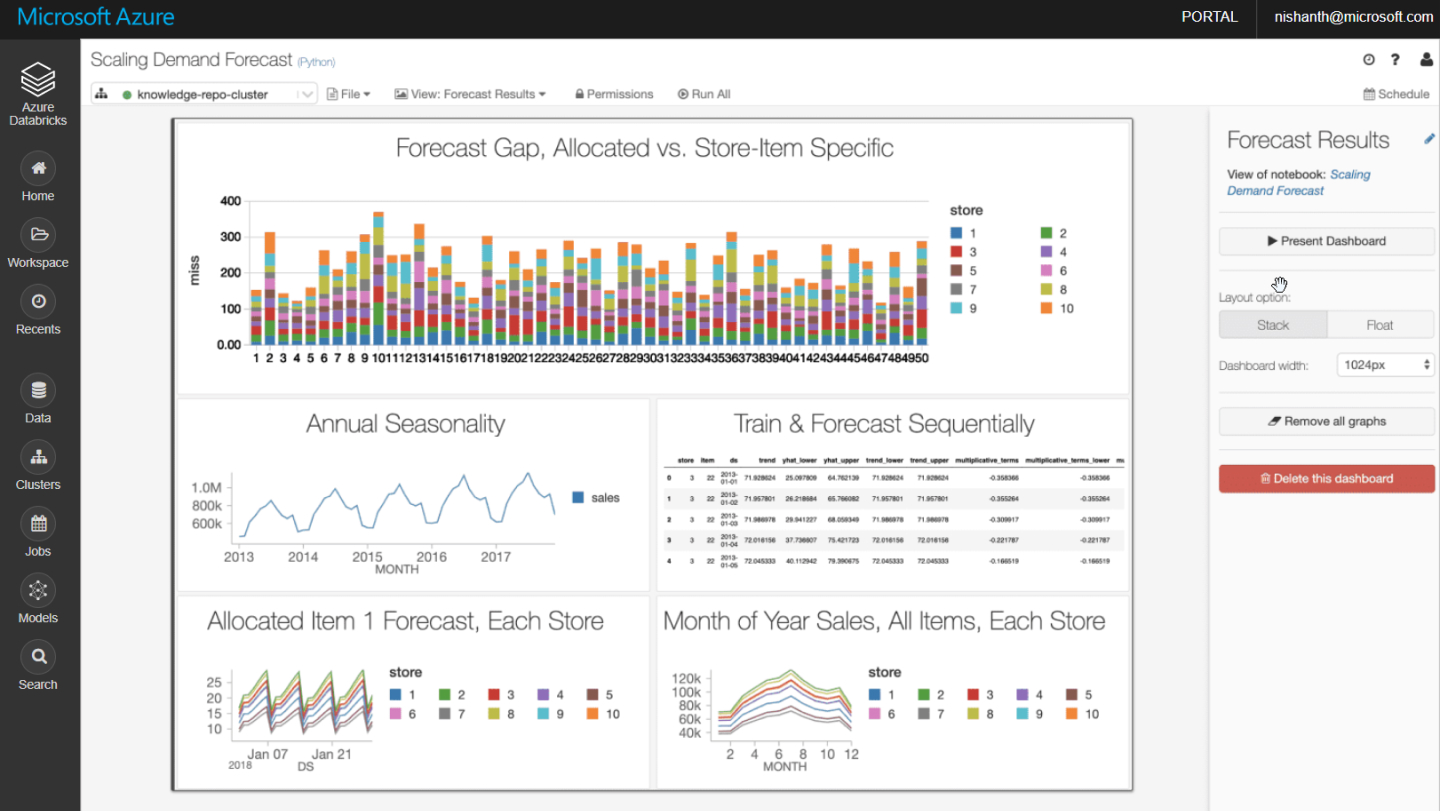
Público objetivo
Temario
¿Qué es y para qué sirve Databricks?
- Determinar cuándo es necesario o recomendable Databricks
- Comparación frente al uso de Dataflows (Data Factory o Power BI), Azure Functions, Azure SQL, etc.
- Presentación y casos de uso reales
- Python vs Scala
- RDD's vs Data Frames/SQL
- Breve presentación de otras API's de Spark: Machine Learning, Streaming y Graph
- Clústeres, notebooks, almacenamiento y jobs
- Repaso del lenguaje Python (enfocado al uso de Pyspark)
- Introducción al concepto de Data Frames / PySparkSQL
- Lectura de datos con PySparkSQL (CSV, JSON, Parquet…)
- Principales funciones de procesamiento y análisis en PySparkSQL (select, filter/where, group by, distinct count...)
- Ejecución de consultas son sintaxis SQL sobre Dataframes
- Escritura de datos (CSV, parquet...)
- Creación de un proceso tipo "Hola Mundo" con PySpark
- Ejercicio fundamental para la lectura (CSV), tratamiento de dataframes, análisis (SQL) y escritura (CSV/parquet)
- Operaciones avanzadas de lectura, join/union y escritura, probando con múltiples formados de entrada/salida
- Funciones de ventana
- Ejercicio caso de uso
Optimización, depuración de procesos y solución de errores
- Operaciones de unión (JOIN y UNION)
- Funciones de ventana (OVER, RANK…)
- Lectura/Escritura de datos avanzada
- Uso de fuentes y destinos comunes en Azure Blob Storage, Data Lake, Azure SQL, Azure Synapse...
- Formato de archivo y compresión recomendados en cada escenario
- Consideraciones para el particionamiento y ejecución distribuida: repartition, coalesce...
- Creación de un proceso tipo "Hola Mundo" con PySpark
- Ejercicio fundamental para la lectura (CSV), tratamiento de dataframes, análisis (SQL) y escritura (CSV/parquet)
- Tipos de clústeres: interactivos y efímeros
- Notebooks vs Jobs
- Planificación automática: Usando Databricks Jobs o Data Fatory, comparación de ventajas entre ambas alternativas
- Integración y despliegue de código continuos en múltiples entornos usando repositorios (ej. GIT) y Azure DevOps Pipelines
Buenas prácticas para abordar las dificultades habituales que encuentran los usuarios
Ejercicios Integrando Azure Databricks y Azure Data Factory
Contacto
Ajustamos cada curso a sus necesidades.
Nuestra oficina en Madrid
- Avenida de Brasil 17. Planta 16
- 28046 Madrid
- info@stratebi.com
- Tlfno: +34 91.788.34.10
- Fax:+34 91.788.57.01