Before organising a course or seminar, we listen to the real needs and objectives of each client, in order to adapt the training and get the most out of it. We tailor each course to your needs.
We are also specialists in 'in company' trainings adapted to the needs of each organisation, where the benefit for several attendees from the same company is much greater. If this is your case, contact us.
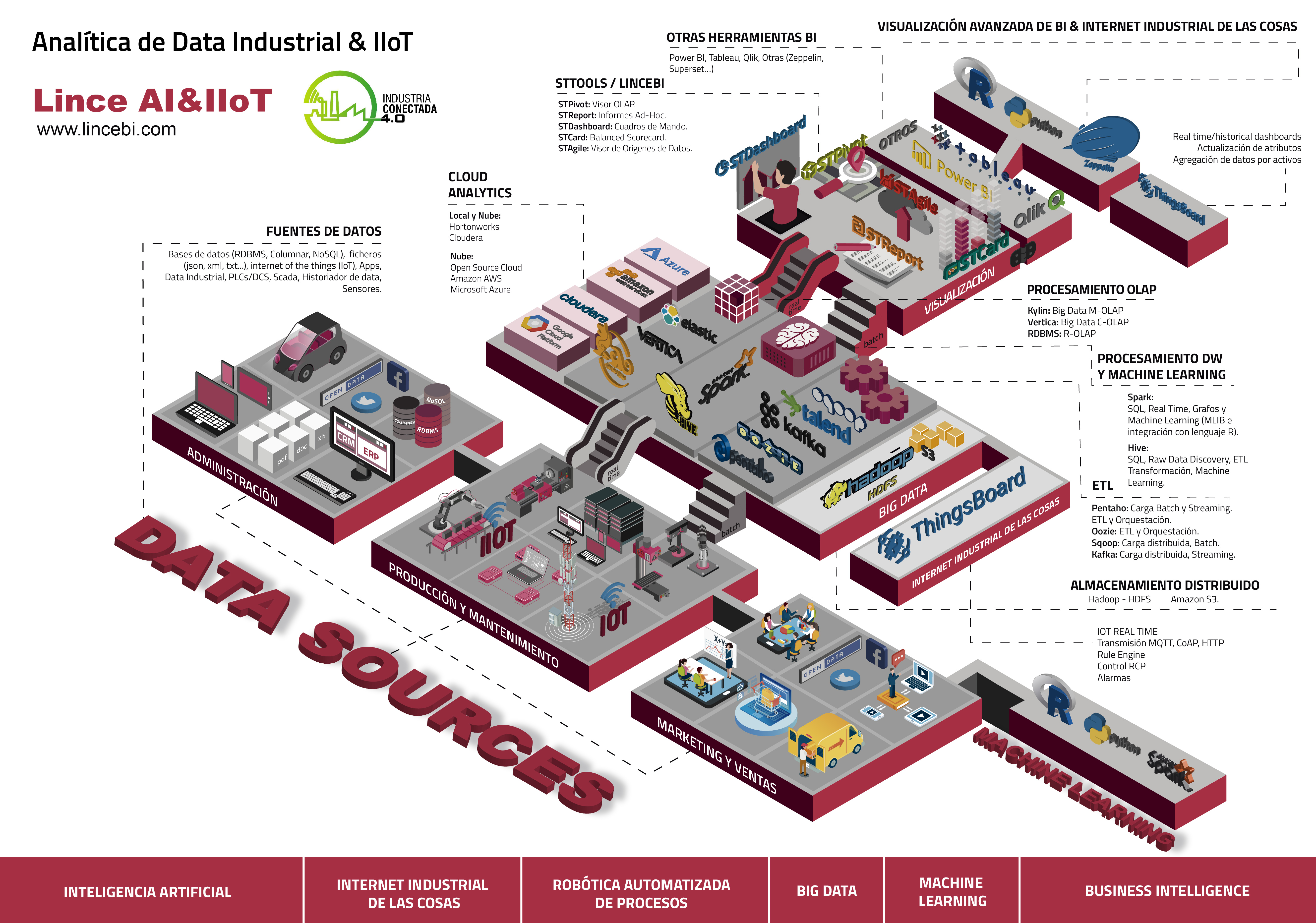
Ponemos a disposición también plataforma Cloud con todas las herramientas instaladas y configuradas, listas para la formación, incluyendo ejercicios, bases de datos, etc... para no perder tiempo en la preparación y configuración inicial. ¡Sólo preocuparos de aprender!
Ofrecemos también la posibilidad de realizar formaciones en base a ‘Casos de Uso’
Se complementa la formación tradicional de un temario/horas/profesor con la realización de casos prácticos en las semanas posteriores al curso en base a datos reales de la propia organización, de forma que se puedan ir poniendo en producción proyectos iniciales con nuestro soporte, apoyo al desarrollo y revisión con los alumnos y equipos, etc…
En los 10 últimos años, ¡hemos formado a más de 250 organizaciones y 3.000 alumnos!
Ah, y regalamos nuestras famosas camisetas de Data Ninjas a todos los asistentes. No te quedes si las tuyas
Curso experto en Data Engineer
Curso experto en Data Engineer
Goal
El curso Experto en Data Engineer tiene como objetivo prepararte para trabajar con las tecnologías, metodologías y algoritmos más avanzados para Big Data.
El curso te formará en la preparación, depuración y explotación de los datos con Apache Spark y Scala. Con ese curso podrás desarrollar, escalar y gestionar tus soluciones y proyectos Data Driven.
Target audiences
Curso destinado para ingenieros o profesionales de TI con conocimiento previo en:
Bases de datos SQL
Conocimientos en lenguajes de scripting (Python, Javascript, R u otras)
Muy interesante esta recopilación que viene haciendo Alexei Grigorev sobre los mejores podcasts sobre el mundo de los Datos, Machine Learning, Inteligencia Artificial... (también hay algunos en español)
Muy buena y clarificadora explicación, desde un punto de vista práctico de las diferencias entre estas dos disciplinas Saber más: Workshops Big Data Analytics
Scala y la necesidad de paralelizar todo “Single-core performance is running out of steam, and you need to parallelize everything” (Martin Odersky , creador de Scala)
Conceptos básicos de Scala
Tipos de datos
Estructuras de control
Conclusiones
Ejercicios prácticos:
Tipos de datos, Colecciones y Estructuras de control en Scala
Caso práctico de procesamiento de datos de AXA con Scala: (Limpieza, filtrado, agregación)
Diseño e implementación de un programa en Spark Streaming para el procesamiento de los datos de Wikipedia en Streaming usando la implementación proporcionada
Caso práctico*: Diseñar la arquitectura para la implementación de un proceso Streaming con datos propios de la organización, usando Kafka y Spark. En el curso se llevaría a cabo el inicio de la implementación y en las tutorías se resolverán dudas surgidas sobre el proceso.